

Selam, umarım keyfiniz yerindedir bu gün güzelinden bir forensic ctf çözeceğiz. Forensic lerde genel olarak incelemeniz için size bir dosya verilir ve bundan bayrağı çıkarmanız beklenir. Farklı bakış açıları çok önemlidir.
Çözüceğim CTF in linki bu picoCTF sitesi üzerinde yayınlanmış. Dilerseniz çözüme geçelim.
Bir dosya indiriyoruz ismi whitepages.txt içine baktığımızda okunabilir karakterlerden oluşmadığını görüyoruz bu yüzden hex editor e atıp bir de o şekilde inceleyelim.
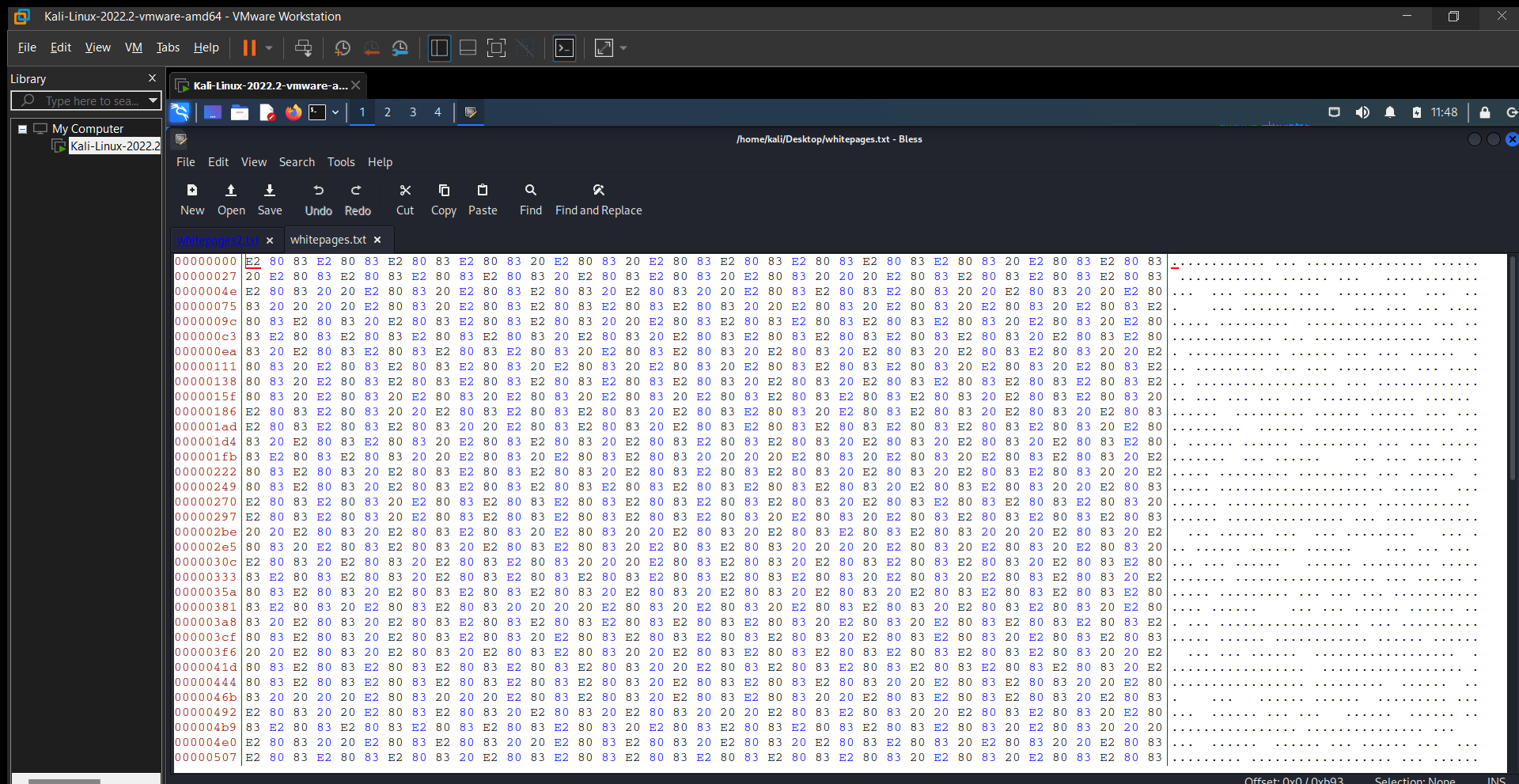
Dosyamızın içeriği bu şekilde, bir resim veyahut ses yada görüntü ile bağdaşmıyacağı ortada çünkü kurtarılabilir bir tarafı yok, demek istediğim bu dosyada bozulmuş bir resim olabileceğine veyahut ses kaydı, görüntü olabileceğine dair hiç bir ipucu yok, başka bir yola başvurmalıyız. (Bazen size bozuk bir png dosyası verirler uzantısını da değiştirirler ve sizin dosyanın içeriğine bakıp onun aslında ne olduğunu anlamanız, bilerek bozulan yerleri tamir ederek resmi bulmanız istenir ama bu ctf de anladığımız kadarıyla işimiz bu değil)
Dosyada dikkat çeken nokta rastgele gözüken karakterlerin bir şekilde kümeler halinde tekrar etmesi, demek istediğim E2 80 83 dizisi sürekli beraber ve aynı dizilişte tekrar ediyor aynı şekilde 20 (boşluk tuşuna tekabül eder) de dosyanın bazı yerlerine yer yer serpiştirilmiş. Bu durumda iki grup var diyebiliriz, 3 değil 4 değil; iki grup... Bu durumda bir deneme yapmamız gerekiyor, aslında deneyeceğimiz başka bir yol da gözükmüyor. Bu grupların binary (ikilik) sisteme çevirmeyi ve elde ettiğimiz sonucu okumaya çalışabiliriz. Evet belki akla hemen gelen bir yöntem değil ama ciddli manada ctf lerde kullanılan taktikler arasındadır.
Şimdi bu şüphemizi denemek için basit bir python kodu yazacağız. Python un dosya okuma fonksiyonu ve modları her zaman kafamı çok karıştırmıştır bu yüzden kodumun tiltliğini mazur görün
Ben böyle bir şey denedim eğer siz daha iyisini ve mantıklısını yazabilirseniz nütfen yazın, çok düşünmedim üzerine sadece işlevselliğinden yararlandım. Basitçe e2 80 83 hex sayılarını 0 ile, 20 hex sayısını ise 1 ile değiştirdim ve oluşan sonucu string olarak döndürdüm aynı zamanda her 8, 0 veya 1 den sonra bir boşluk ekleyerek çıktıyı boşluklara böldüm çünkü bu byte ları okumak için kullanıcağım sitede byte lar arasında boşluk konması gerekiyor, bu kadar.
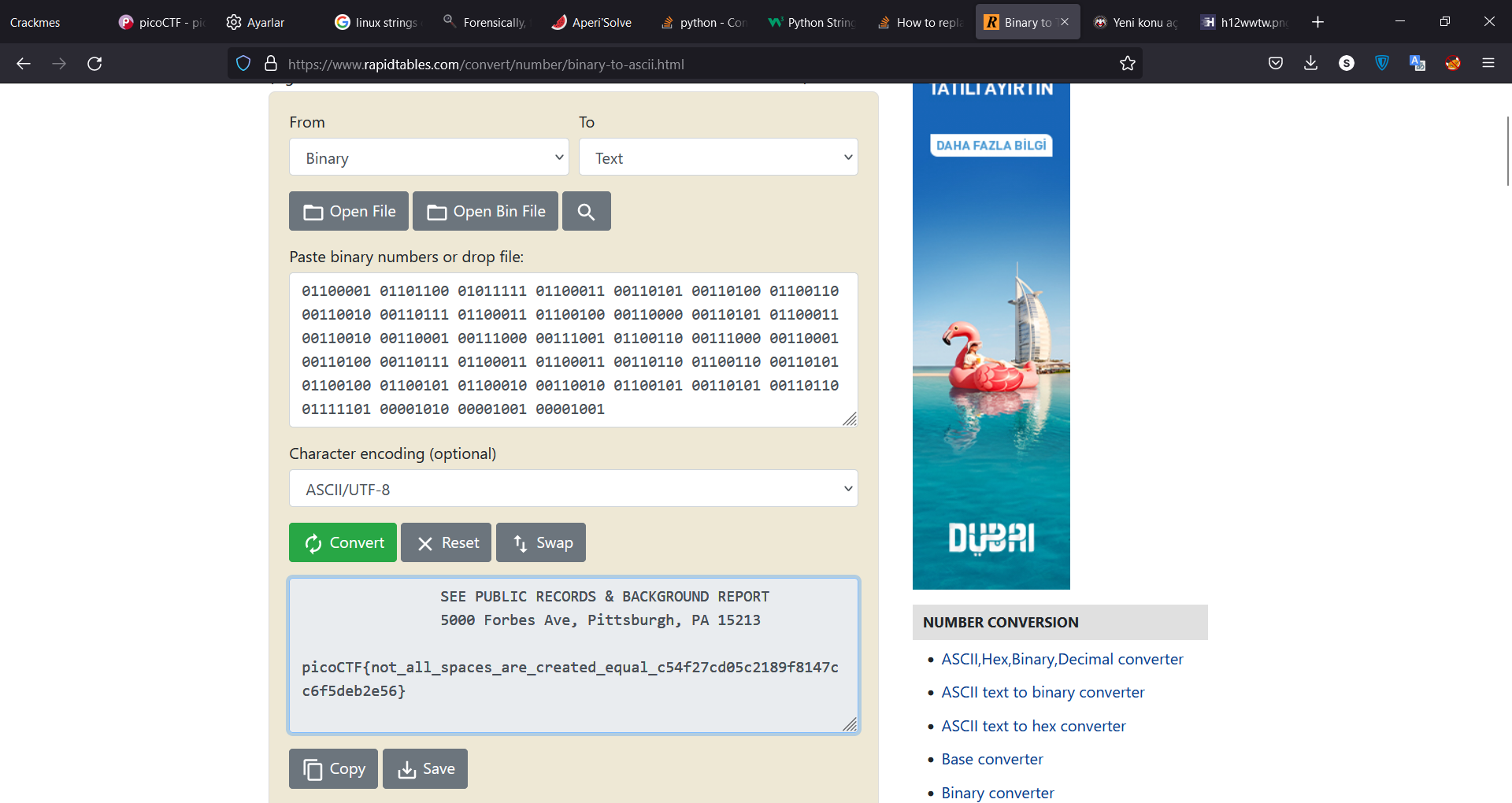
Maksimum iki deneme hakkınız var. hangi grubu 0 veya 1 yapıcağınızın bir kuralı yok, deneyerek; hangi çıktı anlamlı gelirse doğru değiştirme odur ben ilk denememde tutturdum 1 lerin sayıca daha az olmas gerekiceğini düşündüm, ascii karakterlerinin yapısı gereği...
Ve işte bayrağımız:
Anlamadığınız bir şey olursa yada kafanıza takılan, yazmaktan çekinmeyin müsait olduğum sürece cevaplarım. Koduma ve anlatışıma yönelik her türlü yapıcı eleştiriye de sonuna kadar açığım, saygı çerçevesinde tabiki, selametle kalın.
Çözüceğim CTF in linki bu picoCTF sitesi üzerinde yayınlanmış. Dilerseniz çözüme geçelim.
Bir dosya indiriyoruz ismi whitepages.txt içine baktığımızda okunabilir karakterlerden oluşmadığını görüyoruz bu yüzden hex editor e atıp bir de o şekilde inceleyelim.
Dosyamızın içeriği bu şekilde, bir resim veyahut ses yada görüntü ile bağdaşmıyacağı ortada çünkü kurtarılabilir bir tarafı yok, demek istediğim bu dosyada bozulmuş bir resim olabileceğine veyahut ses kaydı, görüntü olabileceğine dair hiç bir ipucu yok, başka bir yola başvurmalıyız. (Bazen size bozuk bir png dosyası verirler uzantısını da değiştirirler ve sizin dosyanın içeriğine bakıp onun aslında ne olduğunu anlamanız, bilerek bozulan yerleri tamir ederek resmi bulmanız istenir ama bu ctf de anladığımız kadarıyla işimiz bu değil)
Dosyada dikkat çeken nokta rastgele gözüken karakterlerin bir şekilde kümeler halinde tekrar etmesi, demek istediğim E2 80 83 dizisi sürekli beraber ve aynı dizilişte tekrar ediyor aynı şekilde 20 (boşluk tuşuna tekabül eder) de dosyanın bazı yerlerine yer yer serpiştirilmiş. Bu durumda iki grup var diyebiliriz, 3 değil 4 değil; iki grup... Bu durumda bir deneme yapmamız gerekiyor, aslında deneyeceğimiz başka bir yol da gözükmüyor. Bu grupların binary (ikilik) sisteme çevirmeyi ve elde ettiğimiz sonucu okumaya çalışabiliriz. Evet belki akla hemen gelen bir yöntem değil ama ciddli manada ctf lerde kullanılan taktikler arasındadır.
Şimdi bu şüphemizi denemek için basit bir python kodu yazacağız. Python un dosya okuma fonksiyonu ve modları her zaman kafamı çok karıştırmıştır bu yüzden kodumun tiltliğini mazur görün
Python:
with open("whitepages.txt", "rb") as f:
bytes = f.read()
binary_metin = ""
bytes = bytes.replace(b"\xe2\x80\x83", b"\x00")
bytes = bytes.replace(b" ", b"\x01")
i = 0
for byte in bytes:
binary_metin += str(byte)
i += 1
if i == 8:
binary_metin += " "
i = 0
print(binary_metin)Ben böyle bir şey denedim eğer siz daha iyisini ve mantıklısını yazabilirseniz nütfen yazın, çok düşünmedim üzerine sadece işlevselliğinden yararlandım. Basitçe e2 80 83 hex sayılarını 0 ile, 20 hex sayısını ise 1 ile değiştirdim ve oluşan sonucu string olarak döndürdüm aynı zamanda her 8, 0 veya 1 den sonra bir boşluk ekleyerek çıktıyı boşluklara böldüm çünkü bu byte ları okumak için kullanıcağım sitede byte lar arasında boşluk konması gerekiyor, bu kadar.
Maksimum iki deneme hakkınız var. hangi grubu 0 veya 1 yapıcağınızın bir kuralı yok, deneyerek; hangi çıktı anlamlı gelirse doğru değiştirme odur ben ilk denememde tutturdum 1 lerin sayıca daha az olmas gerekiceğini düşündüm, ascii karakterlerinin yapısı gereği...
Ve işte bayrağımız:
Anlamadığınız bir şey olursa yada kafanıza takılan, yazmaktan çekinmeyin müsait olduğum sürece cevaplarım. Koduma ve anlatışıma yönelik her türlü yapıcı eleştiriye de sonuna kadar açığım, saygı çerçevesinde tabiki, selametle kalın.

